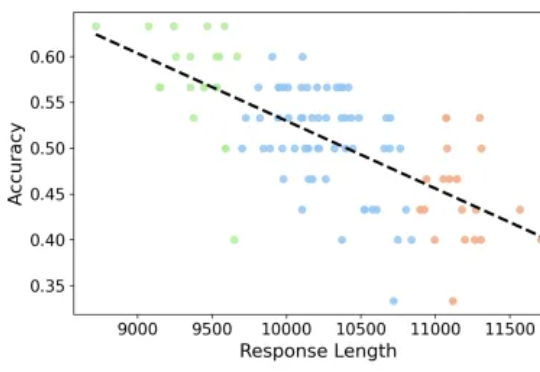
无需训练、只优化解码策略,DTS框架让大模型推理准确率提升6%,推理长度缩短23%
无需训练、只优化解码策略,DTS框架让大模型推理准确率提升6%,推理长度缩短23%专注推理任务的 Large Reasoning Models 在数学基准上不断取得突破,但也带来了一个重要问题:越想越长、越长越错。本文解读由 JHU、UNC Charlotte 等机构团队的最新工作
来自主题: AI技术研报
7936 点击 2025-11-22 11:31
 搜索
搜索
专注推理任务的 Large Reasoning Models 在数学基准上不断取得突破,但也带来了一个重要问题:越想越长、越长越错。本文解读由 JHU、UNC Charlotte 等机构团队的最新工作

Transformer的火种已燃烧七年。如今,推理模型(Reasoning Models)正点燃第二轮革命。Transformer共同作者、OpenAI研究员Łukasz Kaiser预判:未来一两年,AI会极速跃升——瓶颈不在算法,而在GPU与能源。

近期,阿里巴巴 ROLL 团队(淘天未来生活实验室与阿里巴巴智能引擎团队)联合上海交通大学、香港科技大学推出「3A」协同优化框架 ——Async 架构(Asynchronous Training)、Asymmetric PPO(AsyPPO)与 Attention 机制(Attention-based Reasoning Rhythm),
该团队 2025 年的研究《Reasoning by superposition: A theoretical perspective on chain of continuous thought》已从理论上指出,连续思维链的一个关键优势在于它能使模型在叠加(superposition)状态下进行推理:当模型面对多个可能的推理路径而无法确定哪一个是正确时,它可以在连续空间中并行地保留所有可能的路
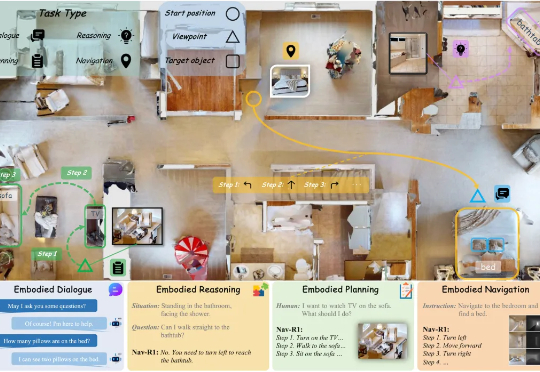
这篇题为《Nav-R1: Reasoning and Navigation in Embodied Scenes》的新论文,提出了一个新的「身体体现式(embodied)基础模型」(foundation model),旨在让机器人或智能体在 3D 环境中能够更好地结合「感知 + 推理 + 行动」。简单说,它不仅「看到 + 听到+开动马达」,还加入清晰的中间「思考」环节。
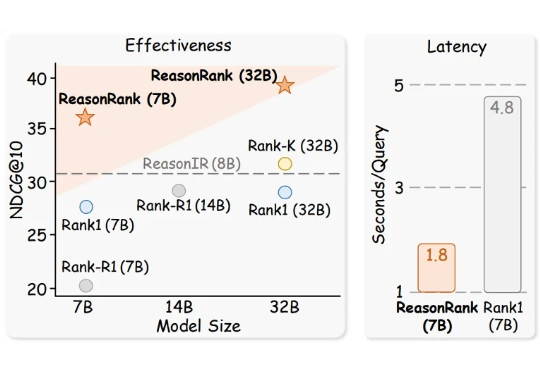
推理大模型(Large Reasoning Model)极大的促进了自然语言处理领域的发展,而信息检索领域的核心问题之一是文档排序,如何利用强大的推理大模型通过主动推理来判断文档的相关性,进而再对文档进行排序是一个值得探索的方向。
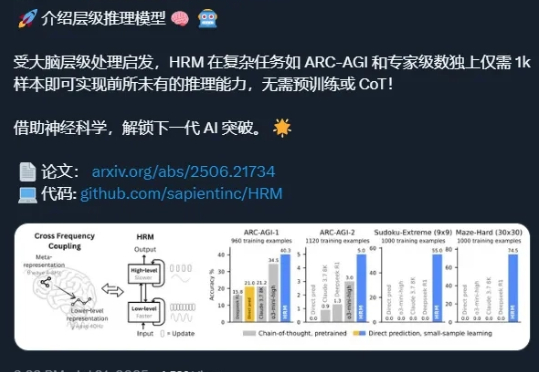
还记得分层推理模型(Hierarchical Reasoning Model,HRM)吗? 这项工作于 6 月份发布,当时引起了不小的轰动——X/Twitter 上的相关讨论获得了超过 400 万的浏览量和数万个点赞,剖析这项工作的 YouTube 视频观看量也超过了 47.5 万次。
27M小模型超越o3-mini-high和DeepSeek-R1!推理还不靠思维链。 开发者是那位拒绝了马斯克、还要挑战Transformer的00后清华校友,Sapient Intelligence的创始人王冠。
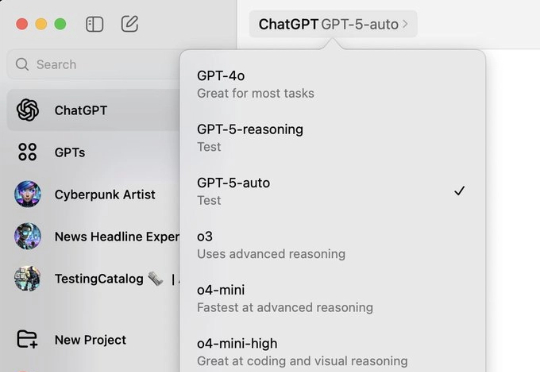
赢了的才是「GPT-5」。 GPT-5 迟迟未现身,网友们开始制作各种梗图「吐槽」其实,这几天关于 GPT-5 的传言就没消停。先是有网友在 macOS ChatGPT 应用中发现了 GPT-5-Auto 和 GPT-5-Reasoning 模型的踪迹:
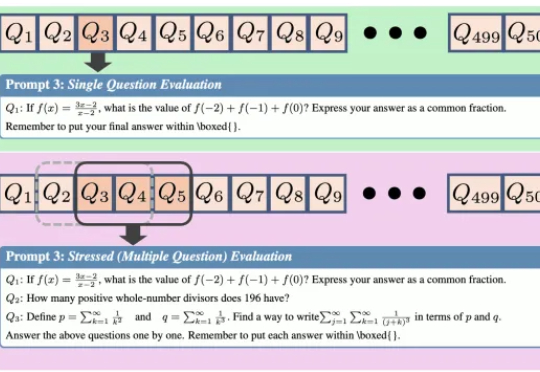
给AI一场压力测试,结果性能暴跌近30%。 来自上海人工智能实验室、清华大学和中国人民大学的研究团队设计了一个全新的“压力测试”框架——REST (Reasoning Evaluation through Simultaneous Testing)。